Welcome to part 2 of our discussion on machine learning and revenue management. In case you missed it, here is part 1 on the basics of machine learning: https://revenueml.com/insights/articles/the-essential-beginners-guide-to-machine-learning
If you need a quick recap, let me offer some takeaways from part 1:
- There are two types of datasets: Labelled (think of your excel sheet with clearly labelled columns) and unlabelled data (think of a drive full of random pictures)
- There are two types of machine learning functions: Supervised (regression and classification tasks) for which you need labelled data and Unsupervised (segmentation) which is used for unlabelled data
Now that you have a basic idea of what “machine learning” actually means, the next question to ask is how you can use machine learning to overcome some of the hurdles that a company faces when coming up with an effective pricing strategy. Remember, machine learning is not just neural networks—it is also a simple linear regression that helps to uncover relationships in your data that you would not have been able to discover otherwise.
Machine learning essentially uses an algorithm to train a machine to sniff out relationships in your dataset and use that to predict what will happen. So, how can we as pricing managers use that to our advantage? Well, here are some very important relationships and forecasts you can measure (or improve your accuracy if you are already calculating these) using machine learning:
- Sales Volume over time
- Elasticity or sales volume response to price change
- The efficiency of our non-price promotions on sales
However, the most important thing to do when incorporating machine learning into your decision-making process is to ask the right business questions before determining the best method to answer. For some of these situations, I will illustrate business questions that can be effectively answered using simple algorithmic calculations.
Predicting Sales
Volume Over Time
It is critical to have precise and extensive input data to ensure accurate sales projections over time. Once you have good data, different machine learning algorithms can be used to improve the accuracy of projections. Remember, you will test these models over a test dataset from the past to assess which model delivers the highest accuracy.
So, what does your business problem look like? Well, here is an example:
- Given the current market conditions, what will my sales look like over the course of next year?
- What will overall market sales look like over the course of next year?
One thing to note when making these kinds of forecasting calculations, is that though you expect market conditions to remain consistent from last year, anomalies can occur. This means you cannot use data from 2018 and 2019 to accurately forecast a pandemic-hit year like 2020. However, you would likely do well using 2020 to forecast 2021 since most people expect it to be similar. In conclusion, understanding external and contextual factors is important in predicting the accuracy of a forecast.
There are two types of models you can use to predict sales volume: time series forecasting and linear regression.
There are two things you need to account for when looking at your training data volume numbers:
- Seasonality
- Trend
A linear regression does not account for seasonality and trend, so you will have to de-trend and de-seasonalize the data first. Time series forecasting is a more advanced way of predicting sales volume over time; these models do account for seasonality and trend. If you are interested in learning more, ARIMA (Autoregressive Integrated Moving Average) is a popular technique but there are several other methods too. You can see an example of ARIMA below:
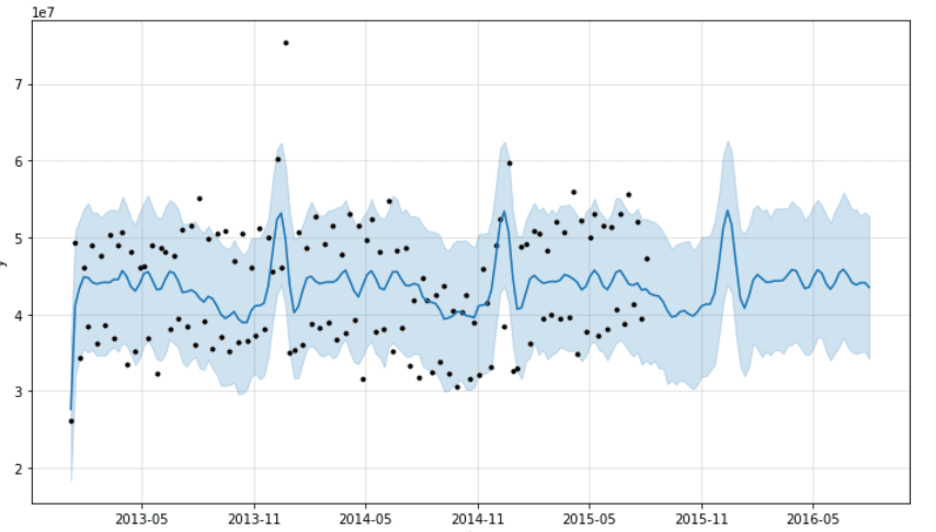
Price Elasticity
Price elasticity is the ultimate test of whether you can take a price increase on a product or not. So, what does your business problem look like? Well, here is an example:
- How much will a price increase affect my sales?
- How much price can I take to increase my overall margin and improve my bottom line?
The traditional approach to drawing up a price response involves an algorithm and machine learning. A simple linear method or a log-log method—both traditional ways of calculating the price response function and determining the relationship between price and sales—use linear regression as the base calculation for uncovering the key metrics.
Of course, the better your company becomes with data granularity, the more nuances you can add to this calculation to make it much more accurate and reflective of market conditions.
Consumer-Driven
Choice Modelling
The traditional approach to price elasticity has several gaps:
- Because these numbers are calculated in isolation, they are not always realistic
- They do not take competitive response and impact into account
A new way to consider an elasticity calculation is to look at it from the consumer-choice perspective. Choice modelling uses a logistic regression to predict market shares rather than absolute volumes. Logistic regressions are classification models and give outputs of an outcome as a probability between 0 and 1. In this case, instead of trying to predict absolute volume—which can be affected by elements like seasonality and trend—trying to predict based on market share normalizes the inputs and reduces variance within the data. This method uses Bayesian statistics to improve upon elasticity and volume projections, using conditional probability to determine which products customers would choose.
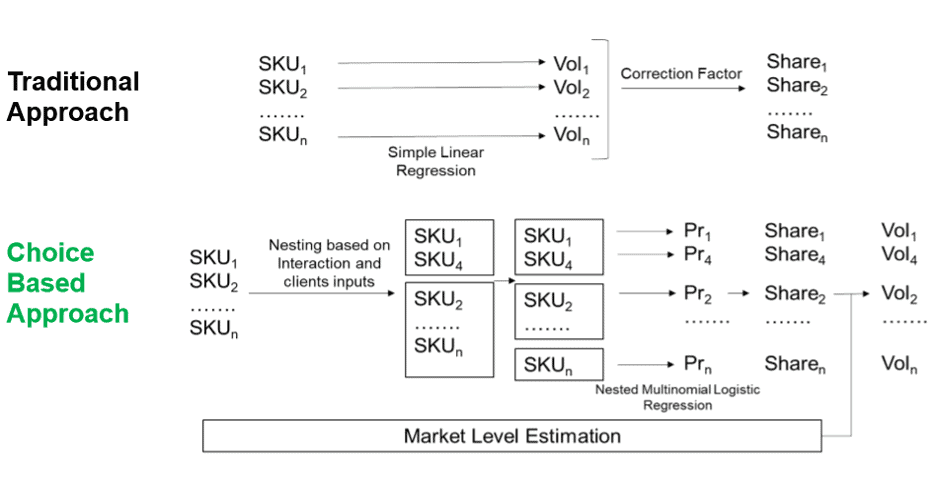
Thus, choice modelling works with two separate models:
- The choice model predicts what share of market each brand in the market will gain
- The sales model predicts what overall volume the category will sell through a market level estimation
Non-Price Promotions
and Effect on Sales
What does your business problem look like in this case?
- How much does a lobby-display promotion affect my sales in a store?
- Which of my products see the biggest impact of these position promotions? I want to optimize my non-price promotions to products that see the biggest impact
So how do we know what impact non-price promotions have on our sales? For example, what impact does a lobby display in a particular store have on one of our brands? Or which brand does this lobby display promotion effect the most?

These are questions that a linear regression can answer very effectively by delineating the relationship between price and volume and other variables in the equation. To do this however, you need categorical variables (i.e., a variable that has a 0 or 1 value) for these promotions. In this example, for each period in the dataset, you will have volume as the dependent variable and two independent variables: price and display. Display will be 1 in periods where lobby display was present and 0 where it was not.
The regression will give you the impact of this display on the sales of the brand. If you want to evaluate other promotions or positions, you can flag them as separate variables in your data (each row of data being a point in time of course). This regression is an example of using machine learning to discover relationships that are not obviously visible and difficult to calculate through any simple metric.
Bad Data, Bad Results
Remember: garbage in, garbage out. This point is very important and needs to be reiterated as often as possible. By using algorithms, machine learning, and data-driven decision-making tools, you are not outsourcing your role in bringing reality and nuance to the numbers. The machine will only ‘learn’ as well as it is taught! If your data is sub-par, has not been cleaned or reflects inaccuracies and biases, your results will reflect those errors and could lead to sub-optimal decisions. Remember, give the data collection and variable selection process a lot of time because your outputs are only as good as your inputs!
ABOUT THE AUTHOR Farhan Ahmed is a Consultant at Revenue Management Labs. Revenue Management Labs helps companies develop and execute practical solutions to maximize long-term revenue and profitability. Connect with Farhan at fahmed@revenueml.com





